
Phần 1: https://kenkai.vn/cong-nghe/giai-thich-cac-mo-hinh-tri-tue-nhan-tao-tao-sinh-%f0%9f%a4%96phan-1/
Variational Autoencoders (VAEs)
Bộ mã hóa tự động biến phân (Variational Autoencoders – VAEs)
Các mô hình dựa trên VAE (Variational Autoencoders) được giới thiệu lần đầu tiên vào năm 2013 bởi Diederik P. Kingma và Max Welling, và từ đó đã trở thành một loại mô hình sinh tạo phổ biến.
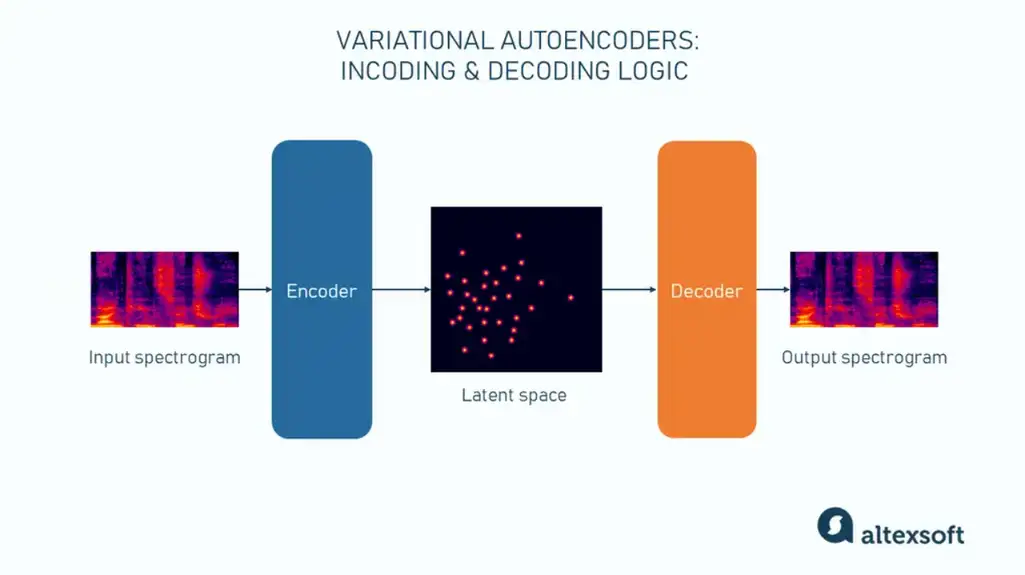
A variational autoencoder is an unsupervised neural network consisting of two parts: an encoder and a decoder. During the training stage, an encoder learns to compress input data into a simplified representation (so-called latent space, which is lower-dimensional than the original data) that captures only essential features of the initial input. Each data point isn’t represented by a single value but by a probabilistic distribution of values. This built-in randomness is what gives the autoencoder its “variational” characteristic.
Một bộ mã hóa tự động biến phân (variational autoencoder) là một mạng nơ-ron không giám sát bao gồm hai phần: một bộ mã hóa và một bộ giải mã. Trong giai đoạn huấn luyện, bộ mã hóa học cách nén dữ liệu đầu vào thành một biểu diễn đơn giản hóa (còn gọi là không gian tiềm ẩn, có chiều thấp hơn dữ liệu gốc) chỉ bao gồm các đặc trưng cốt lõi của đầu vào ban đầu. Mỗi điểm dữ liệu không được biểu diễn bằng một giá trị đơn lẻ mà bằng một phân phối xác suất các giá trị. Tính ngẫu nhiên được xây dựng sẵn này là điều tạo nên đặc trưng “biến phân” của bộ mã hóa tự động.
Think of latent representations as the DNA of an organism. DNA holds the core instructions needed to build and maintain a living being. Similarly, latent representations contain the fundamental elements of data, allowing the model to regenerate the original information from this encoded essence. But if you change the DNA molecule just a little bit, you get a completely different organism. For example, did you know that human and chimpanzee DNA is 98-99 percent identical?
Hãy nghĩ về các biểu diễn tiềm ẩn như là DNA của một sinh vật. DNA chứa những hướng dẫn cốt lõi cần thiết để xây dựng và duy trì một sinh vật sống. Tương tự, các biểu diễn tiềm ẩn chứa những yếu tố cơ bản của dữ liệu, cho phép mô hình tái tạo lại thông tin gốc từ bản chất được mã hóa này. Nhưng nếu bạn thay đổi phân tử DNA chỉ một chút, bạn sẽ nhận được một sinh vật hoàn toàn khác. Ví dụ, bạn có biết rằng DNA của con người và tinh tinh giống nhau 98-99 phần trăm?
A decoder takes latent representation as input and reverses the process. But it doesn’t reconstruct the exact input; instead, it creates something new resembling typical examples from the dataset.
Một bộ giải mã lấy biểu diễn tiềm ẩn làm đầu vào và đảo ngược quá trình. Nhưng nó không tái tạo chính xác đầu vào; thay vào đó, nó tạo ra một cái gì đó mới giống với các ví dụ điển hình từ tập dữ liệu.
VAEs excel in tasks like image and sound generation, as well as image denoising.
VAE rất xuất sắc trong các tác vụ như tạo ra hình ảnh và âm thanh, cũng như khử nhiễu hình ảnh.
Types of generative AI applications with examples and use cases
Các loại ứng dụng trí tuệ nhân tạo sinh tạo với ví dụ và trường hợp sử dụng
Trí tuệ nhân tạo sinh tạo (Generative AI) có rất nhiều ứng dụng thực tiễn trong các lĩnh vực khác nhau như thị giác máy tính, nơi nó có thể tăng cường kỹ thuật tăng cường dữ liệu. Tiềm năng của việc sử dụng mô hình sinh tạo thực sự là vô hạn. Bên dưới đây bạn sẽ tìm thấy một số trường hợp sử dụng nổi bật đã mang lại kết quả đáng kinh ngạc. Hoặc xem video của chúng tôi về chủ đề này.
Image generation
Tạo hình ảnh
Trường hợp sử dụng nổi bật nhất của trí tuệ nhân tạo sinh tạo là tạo ra các hình ảnh giả mạo trông giống như thật. Ví dụ, vào năm 2017, Tero Karras – một Nhà khoa học nghiên cứu nổi tiếng tại NVIDIA Research – đã công bố “Progressive Growing of GANs for Improved Quality, Stability, and Variation.”

Trong bài báo này, ông đã minh họa việc tạo ra các bức ảnh chân thực về khuôn mặt con người. Mô hình này được huấn luyện trên dữ liệu đầu vào chứa các bức ảnh thật của các ngôi sao nổi tiếng, sau đó nó tạo ra các bức ảnh mới chân thực về khuôn mặt con người có một số đặc điểm của các ngôi sao nổi tiếng, khiến chúng có vẻ quen thuộc. Chẳng hạn, cô gái trong ảnh ở góc trên bên phải trông hơi giống Beyoncé, nhưng đồng thời cũng rõ ràng là không phải là nữ ca sĩ này.
Image-to-image translation
Chuyển đổi từ hình ảnh sang hình ảnh
Như tên gọi đề xuất, trí tuệ nhân tạo sinh tạo biến đổi một loại hình ảnh thành một loại khác. Có một loạt các biến thể chuyển đổi từ hình ảnh sang hình ảnh.
Style transfer. Nhiệm vụ này liên quan đến việc trích xuất phong cách từ một bức tranh nổi tiếng và áp dụng nó vào một hình ảnh khác. Ví dụ, chúng ta có thể lấy một bức ảnh thực sự chúng tôi chụp ở Cologne, Đức, và chuyển đổi nó thành phong cách của bức tranh của Van Gogh.

Sketches-to-realistic images. Chuyển đổi từ phác thảo sang hình ảnh thực tế. Ở đây, người dùng bắt đầu với một phác thảo thưa thớt và danh mục đối tượng mong muốn, và mạng lưới sau đó sẽ đề xuất sự hoàn thành hợp lý của nó và hiển thị một hình ảnh tổng hợp tương ứng.

Một trong những bài báo thảo luận về công nghệ này là “DeepFaceDrawing: Deep Generation of Face Images from Sketches“. Nó được công bố vào năm 2020 bởi một nhóm các nhà nghiên cứu đến từ Trung Quốc. Nó mô tả cách các phác thảo chân dung đơn giản có thể được chuyển đổi thành những bức ảnh chân thực về con người.
MRI thành các bản quét CT (MRI into CT scans). Trong lĩnh vực chăm sóc sức khỏe (healthcare), một ví dụ có thể là chuyển đổi một hình ảnh MRI thành một bản quét CT (MRI image into a CT scan) vì một số liệu pháp đòi hỏi hình ảnh từ cả hai phương thức chụp. Tuy nhiên, CT, đặc biệt là khi cần độ phân giải cao (high resolution), đòi hỏi một liều lượng bức xạ khá cao cho bệnh nhân. Do đó, bạn chỉ có thể thực hiện MRI và tổng hợp một hình ảnh CT từ nó (do an MRI and synthesize a CT image from it).
Text-to-image translation
Chuyển đổi từ văn bản sang hình ảnh
Phương pháp này ngụ ý sản xuất các hình ảnh khác nhau (thực tế, giống như tranh vẽ, v.v.) từ các mô tả bằng văn bản về các đối tượng đơn giản.

Bức ảnh ở trên là một ví dụ về chuyển đổi từ văn bản sang hình ảnh. Các bộ tạo hình ảnh AI phổ biến nhất là Midjourney, Dall-e của OpenAI và Stable Diffusion đã đề cập trước đó.
Để tạo ra bức ảnh mà bạn thấy bên dưới, chúng tôi đã cung cấp cho Stable Diffusion các từ khóa sau: một giấc mơ về thời gian đã qua, tranh dầu, đỏ xanh trắng, canvas, màu nước, cá chép, và động vật. Kết quả không hoàn hảo, nhưng khá ấn tượng, xét cho đến việc chúng tôi không có quyền truy cập vào phiên bản beta ban đầu với một tập hợp tính năng rộng hơn mà chỉ sử dụng một công cụ của bên thứ ba.

Kết quả của tất cả các chương trình này khá tương tự nhau. Tuy nhiên, một số người dùng lưu ý rằng, trung bình, Midjourney vẽ một chút biểu cảm hơn, và Stable Diffusion tuân theo yêu cầu một cách rõ ràng hơn ở các cài đặt mặc định.
Text-to-speech
Chuyển đổi từ văn bản sang giọng nói
Các nhà nghiên cứu cũng đã sử dụng GAN để tạo ra giọng nói tổng hợp từ đầu vào văn bản. Các công nghệ học sâu tiên tiến như Amazon Polly và DeepMind tổng hợp giọng nói người tự nhiên. Các mô hình như vậy hoạt động trực tiếp trên các chuỗi đầu vào ký tự hoặc âm tiết và tạo ra đầu ra âm thanh nói thô.
Audio generation
Tạo ra âm thanh
Trí tuệ nhân tạo sinh tạo cũng có thể xử lý dữ liệu âm thanh. Để làm điều này, trước tiên bạn cần chuyển đổi tín hiệu âm thanh thành các biểu diễn 2 chiều giống như hình ảnh được gọi là phổ âm. Điều này cho phép chúng ta sử dụng các thuật toán được thiết kế cụ thể để làm việc với hình ảnh như CNN cho nhiệm vụ liên quan đến âm thanh của chúng ta.
Sử dụng phương pháp này, bạn có thể biến đổi giọng nói của mọi người hoặc thay đổi phong cách/thể loại của một đoạn nhạc. Ví dụ, bạn có thể “chuyển đổi” một đoạn nhạc từ phong cách cổ điển sang phong cách jazz.
Vào năm 2022, Apple đã mua lại startup AI Music của Anh để tăng cường khả năng âm thanh của Apple. Công nghệ được phát triển bởi startup này cho phép tạo ra các bản nhạc nền bằng cách sử dụng các bản nhạc công cộng miễn phí được xử lý bởi các thuật toán AI của hệ thống. Nhiệm vụ chính là thực hiện phân tích âm thanh và tạo ra các bản nhạc nền “động” có thể thay đổi tùy thuộc vào cách người dùng tương tác với chúng. Điều đó có nghĩa là nhạc có thể thay đổi theo không khí của cảnh trong trò chơi hoặc tùy thuộc vào cường độ của bài tập tại phòng gym của người dùng.
Video generation
Tạo video
Đây là một tập hợp các hình ảnh động. Do đó, logic, các video cũng có thể được tạo ra và chuyển đổi theo cách tương tự như hình ảnh. Trong khi năm 2023 được đánh dấu bởi những bước đột phá trong LLM và sự bùng nổ của các công nghệ tạo hình ảnh, năm 2024 đã chứng kiến những tiến bộ đáng kể trong lĩnh vực tạo video. Vào đầu năm 2024, OpenAI đã giới thiệu một mô hình chuyển đổi từ văn bản sang video thực sự ấn tượng có tên là Sora.
Sora là một mô hình dựa trên khuếch tán (diffusion) tạo ra video từ nhiễu tĩnh. Nó có thể tạo ra các cảnh phức tạp với nhiều nhân vật, các chuyển động cụ thể và các chi tiết chính xác về chủ thể và nền. Tương tự như các mô hình GPT, Sora cũng sử dụng kiến trúc transformer để làm việc với các lời nhắc văn bản. Ngoài việc tạo video từ văn bản, Sora còn có thể hoạt hình các hình ảnh tĩnh hiện có.
Image and video resolution enhancement
Nâng cao độ phân giải hình ảnh và video
Nếu chúng ta có một hình ảnh chất lượng kém, chúng ta có thể sử dụng một mô hình GAN để tạo ra một phiên bản tốt hơn bằng cách xác định từng điểm ảnh riêng lẻ và sau đó tạo ra một độ phân giải cao hơn của đó.

Chúng ta có thể nâng cấp hình ảnh từ các bộ phim cũ bằng cách phóng to chúng lên 4K và hơn thế nữa, tạo ra nhiều khung hình mỗi giây (ví dụ: 60 fps thay vì 23), và thêm màu sắc vào các bộ phim đen trắng.
Synthetic data generation
Tạo dữ liệu tổng hợp
Trong khi chúng ta sống trong một thế giới tràn ngập dữ liệu được tạo ra liên tục với số lượng lớn, vấn đề thu thập đủ dữ liệu để huấn luyện các mô hình học máy vẫn còn tồn tại. Thu thập đủ mẫu chất lượng cao để huấn luyện là một nhiệm vụ tốn thời gian, tốn kém và thường là không thể thực hiện. Giải pháp cho vấn đề này có thể là dữ liệu tổng hợp, phụ thuộc vào trí tuệ nhân tạo sinh tạo.
Dựa trên các công nghệ mới của NVIDIA trong lĩnh vực trí tuệ nhân tạo sinh tạo, công ty đã phát triển một khung làm việc học sâu mới gọi là fVDB. Khung này có thể tạo ra các mô hình 3D quy mô lớn và độ phân giải cao của các môi trường đô thị thực tế. Điều này cho phép tạo ra các biểu diễn ảo sẵn sàng cho trí tuệ nhân tạo, có thể được sử dụng để huấn luyện các hệ thống tự động, mô hình hóa khí hậu và lập kế hoạch đô thị.
fVDB được xây dựng dựa trên công việc hiện có của NVIDIA với thư viện OpenVDB, bổ sung thêm các toán tử dựa trên trí tuệ nhân tạo cho các tác vụ như tái tạo 3D, mô hình hóa sinh tạo và kết xuất theo thời gian thực. Điều này cho phép tạo ra các bản sao kỹ thuật số chi tiết và chính xác về không gian của thế giới vật lý.
Dữ liệu tổng hợp như vậy có thể giúp phát triển xe tự lái vì chúng có thể sử dụng các tập dữ liệu huấn luyện thế giới ảo được tạo ra để phát hiện người đi bộ, ví dụ.

The dark side of generative AI: Is it that dark?
Mặt tối của trí tuệ nhân tạo sinh tạo: Nó có thực sự tối tăm không?
Dù là công nghệ nào, nó đều có thể được sử dụng vì cả mục đích tốt và xấu. Tất nhiên, trí tuệ nhân tạo sinh tạo cũng không phải là ngoại lệ. Hiện tại, một vài thách thức tồn tại.
Pseudo-images and deep fakes. Ảnh giả và deepfake. Ban đầu được tạo ra cho mục đích giải trí, công nghệ deepfake đã nhận được một danh tiếng xấu. Có sẵn công khai cho tất cả người dùng thông qua phần mềm như FakeApp, Reface và DeepFaceLab, deepfake đã được sử dụng bởi mọi người không chỉ để vui đùa mà còn cho các hoạt động độc hại.
Ví dụ, vào tháng 3 năm 2022, một video deepfake của Tổng thống Ukraine Volodymyr Zelensky yêu cầu người dân đầu hàng đã được phát sóng trên các kênh truyền thông Ukraine bị hack. Mặc dù có thể nhìn thấy rõ ràng rằng video là giả, nó vẫn lọt ra mạng xã hội và gây ra nhiều sự thao túng.
The risk of losing control. Rủi ro mất kiểm soát. Khi nói điều này, chúng ta không có ý nói rằng ngày mai, máy móc sẽ nổi dậy chống lại nhân loại và phá hủy thế giới. Hãy thành thật, chính chúng ta cũng khá giỏi trong việc này. Tuy nhiên, do trí tuệ nhân tạo sinh tạo có thể tự học, hành vi của nó rất khó kiểm soát. Các kết quả được cung cấp thường có thể rất khác với những gì bạn mong đợi.
Nhưng như chúng ta biết, công nghệ sẽ không thể phát triển và lớn mạnh mà không có những thách thức. Hơn nữa, trí tuệ nhân tạo có trách nhiệm (responsible AI) làm cho việc tránh hoặc giảm thiểu hoàn toàn những nhược điểm của các đổi mới như trí tuệ nhân tạo sinh tạo trở nên có thể.
Nhưng đừng lo: Bài viết bạn vừa đọc không được tạo ra bởi trí tuệ nhân tạo.
Hay là nó được viết bởi AI?
Phần 1: https://kenkai.vn/cong-nghe/giai-thich-cac-mo-hinh-tri-tue-nhan-tao-tao-sinh-%f0%9f%a4%96phan-1/
Tác giả: altexsoft.com,
Link bài gốc: Generative AI Models Explained | Bài được cập nhật lần cuối vào Ngày 05 tháng 09 năm 2024 | www.altexsoft.com
Dịch giả: Dieter R – KenkAI Nhiều thứ hay
(*) Bản quyền bản dịch thuộc về Dieter R. Tuy nhiên, nội dung bài viết không phải do tôi tạo ra. Mọi khiếu nại về bản quyền (nếu có) xin vui lòng gửi email đến địa chỉ purchasevn@getkenka.com. Xin chân thành cảm ơn.
(**) Follow KenkAI Nhiều thứ hay để đọc các bài dịch khác và cập nhật thông tin bổ ích hằng ngày.
Để lại một bình luận