

Chắc chắn bạn đã nhận thấy rằng hình ảnh trên được tạo ra bởi trí tuệ nhân tạo – cụ thể là Midjourney. Tuy nhiên, việc dịch chuyển từ văn bản sang hình ảnh (text-to-image translation) chỉ là một trong nhiều ví dụ về những gì các mô hình trí tuệ nhân tạo sinh tạo làm ngày nay. Những nhà sáng tạo kỹ thuật số này đang giúp với các công việc nhàm chán (tedious tasks), thiết kế, viết và xây dựng mọi thứ từ trang web đến các bản nhạc nhanh hơn chúng ta có thể đánh vần algorithm (thuật toán).
Tác động của trí tuệ nhân tạo sinh tạo đối với các doanh nghiệp trong các lĩnh vực khác nhau là rất lớn và tiếp tục tăng lên. Theo một cuộc khảo sát gần đây của Gartner, các chủ doanh nghiệp đã báo cáo về giá trị thiết yếu được thu được từ các sáng kiến GenAI: tăng doanh thu trung bình 16%, tiết kiệm chi phí 15% và cải thiện năng suất 23%.
Sẽ là một sai lầm lớn nếu chúng ta không chú ý đúng mức đến chủ đề này. Vì vậy, bài đăng này sẽ giải thích về các mô hình trí tuệ nhân tạo sinh tạo, cách chúng hoạt động và các ứng dụng thực tiễn của chúng trong các lĩnh vực khác nhau.
What is generative AI?
Generative AI là gì?
Trí tuệ nhân tạo sinh tạo đề cập đến các thuật toán học máy không giám sát và bán giám sát cho phép máy tính sử dụng nội dung hiện có như văn bản, tệp âm thanh và video, hình ảnh và thậm chí mã để tạo ra nội dung mới có thể. Ý chính là tạo ra các tác phẩm hoàn toàn mới nguyên bản trông giống như thật.

Trí tuệ nhân tạo sinh tạo cho phép máy tính trừu tượng hóa các mẫu cơ bản liên quan đến dữ liệu đầu vào để mô hình có thể tạo ra hoặc xuất ra nội dung mới.
Về hiện tại, có nhiều mô hình trí tuệ nhân tạo sinh tạo được sử dụng rộng rãi nhất, và chúng ta sẽ xem xét kỹ bốn trong số chúng.
- Generative Adversarial Networks (Mạng đối kháng sinh tạo), hay GANs – là những công nghệ có thể tạo ra các tác phẩm hình ảnh và đa phương tiện từ cả dữ liệu đầu vào là hình ảnh và văn bản.
- Transformer-based models Các mô hình dựa trên Transformer – bao gồm các công nghệ như các mô hình ngôn ngữ Generative Pre-Trained (GPT) có thể dịch và sử dụng thông tin thu thập trên Internet để tạo ra nội dung văn bản.
- Variational Autoencoders Bộ mã hóa biến phân (VAEs) được sử dụng trong các tác vụ như tạo hình ảnh và phát hiện bất thường.
- Diffusion models vượt trội trong việc tạo ra hình ảnh và video thực tế từ nhiễu ngẫu nhiên (các tập hợp dữ liệu ngẫu nhiên).
Để hiểu ý tưởng đằng sau trí tuệ nhân tạo sinh tạo, chúng ta cần xem xét sự khác biệt giữa mô hình phân biệt (discriminative modeling) và mô hình sinh tạo (generative modeling).
How does gen AI work: discriminative vs generative modeling
Trí tuệ nhân tạo sinh tạo hoạt động như thế nào: mô hình phân biệt so với mô hình sinh tạo
Mô hình phân biệt được sử dụng để phân loại các điểm dữ liệu hiện có (ví dụ: hình ảnh mèo và heo tenin vào các danh mục tương ứng). Nó chủ yếu thuộc về các tác vụ học máy có giám sát (supervised machine learning).
Mô hình sinh tạo cố gắng hiểu cấu trúc tập dữ liệu và tạo ra các ví dụ tương tự (ví dụ: tạo ra một bức ảnh thực tế của một con heo tenin hoặc một con mèo). Nó chủ yếu thuộc về các tác vụ học máy không giám sát và bán giám sát (unsupervised and semi-supervised machine learning).
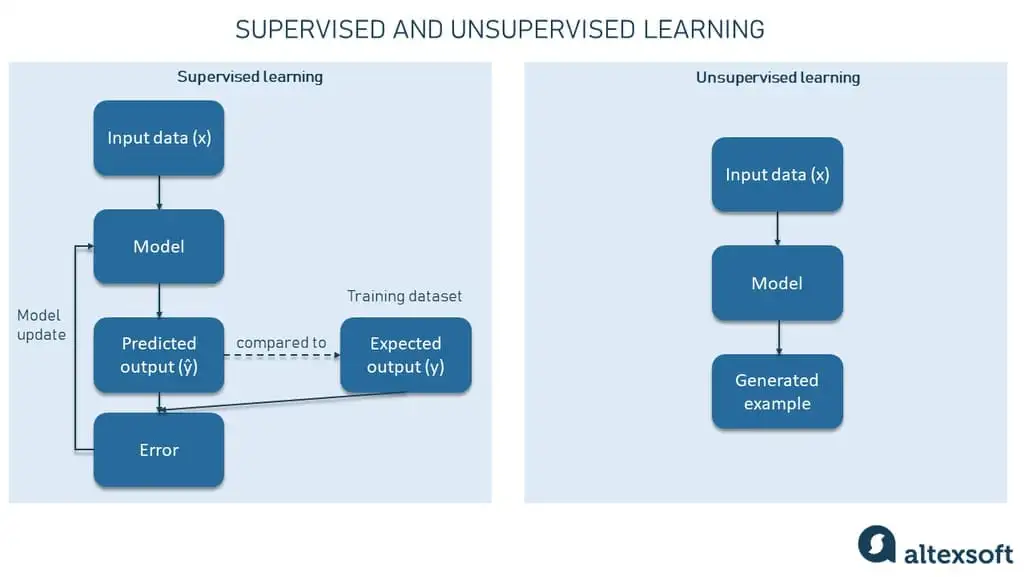
Càng nhiều mạng nơ-ron xâm nhập vào cuộc sống của chúng ta, thì lĩnh vực mô hình phân biệt và mô hình sinh tạo càng phát triển. Hãy thảo luận chi tiết hơn về mỗi lĩnh vực này.
Discriminative modeling
Mô hình phân biệt
Hầu hết các mô hình học máy được sử dụng để đưa ra dự đoán. Các thuật toán phân biệt cố gắng phân loại dữ liệu đầu vào dựa trên một số đặc trưng và dự đoán nhãn hoặc lớp mà một ví dụ dữ liệu (quan sát) nhất định thuộc về.
Giả sử chúng ta có dữ liệu huấn luyện chứa nhiều hình ảnh của mèo và heo tenin. Những thứ này cũng được gọi là mẫu. Mỗi mẫu đi kèm với một tập các đặc trưng (X) và một nhãn lớp (Y), trong trường hợp của chúng ta, có thể là “mèo” hoặc “heo tenin”. Chúng ta cũng có một mạng nơ-ron nhằm hiểu cách phân biệt giữa hai lớp và dự đoán xác suất một mẫu nhất định thuộc về một trong hai lớp đó.
Trong quá trình huấn luyện, mỗi dự đoán (ŷ) được so sánh với nhãn thực tế (Y). Dựa trên sự khác biệt giữa hai giá trị này, mô hình dần dần học được mối quan hệ giữa các đặc trưng và các lớp, và tương quan kết quả của nó.
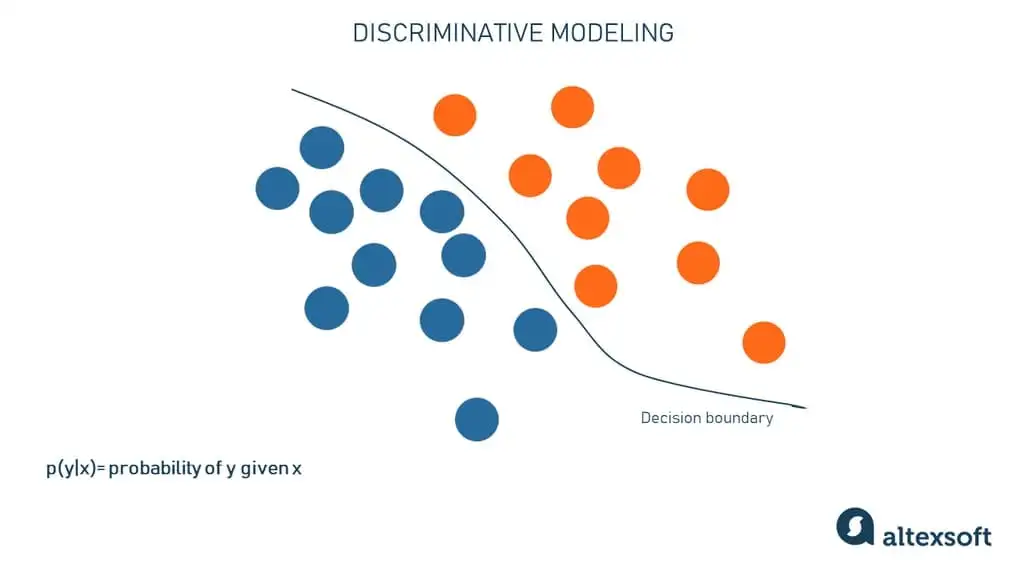
Hãy giới hạn sự khác biệt giữa mèo và heo tenin chỉ trong hai đặc trưng trong tập đặc trưng X (ví dụ, “sự có mặt của đuôi” và “hình dạng của tai”). Vì mỗi đặc trưng là một chiều, nó sẽ dễ dàng trình bày chúng trong không gian dữ liệu 2 chiều. Trong hình minh họa trên, các chấm xanh dương là heo tenin, và các chấm cam là mèo. Đường thẳng biểu diễn ranh giới quyết định hoặc mô hình phân biệt đã học để phân tách mèo khỏi heo tenin dựa trên những đặc trưng đó.
Khi mô hình này đã được huấn luyện, nó sẽ kiểm tra xem một bức ảnh mới sẽ rơi vào phía nào của ranh giới quyết định. Để làm điều này, mô hình, theo một cách nào đó, chỉ “nhớ lại” vật thể trông như thế nào từ những gì nó đã thấy.
Để tóm lại, mô hình phân biệt kiểu như nén thông tin về sự khác biệt giữa mèo và heo tenin, mà không cố gắng hiểu một con mèo là gì và một con heo tenin là gì.
Generative modeling
Mô hình sinh tạo
Các thuật toán sinh tạo làm hoàn toàn ngược lại – thay vì dự đoán một nhãn được gán cho một số đặc trưng, chúng cố gắng dự đoán các đặc trưng dựa trên một nhãn nhất định. Các thuật toán phân biệt quan tâm đến mối quan hệ giữa X và Y; các mô hình sinh tạo quan tâm đến cách bạn có được X từ Y.
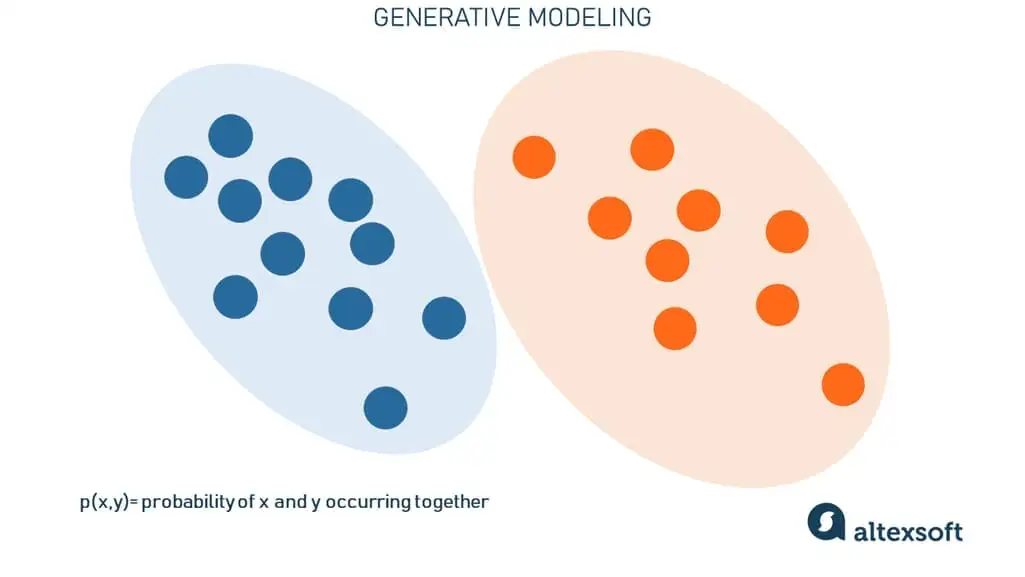
Về mặt toán học, mô hình sinh tạo cho phép chúng ta nắm bắt xác suất của x và y xảy ra cùng nhau. Nó tập trung vào việc học các đặc trưng và mối quan hệ của chúng để có ý tưởng về những gì khiến mèo trông giống mèo và heo tenin trông giống heo tenin. Kết quả là, những thuật toán như vậy không chỉ phân biệt được hai con vật mà còn tái tạo hoặc tạo ra hình ảnh của chúng.
Bạn có thể tự hỏi, “Tại sao chúng ta lại cần các thuật toán discriminative algorithms?” Sự thật là chúng dễ giám sát và giải thích hơn (explainable) – với những từ khác, bạn có thể hiểu tại sao mô hình đi đến một kết luận nhất định (why the model comes to a certain conclusion).
Ngoài ra, trong nhiều trường hợp không quan trọng dữ liệu được tạo ra như thế nào – chúng ta chỉ cần biết nó thuộc về danh mục nào, và đó chính xác là nơi mà các mô hình phân biệt vượt trội. Hãy nghĩ về phân tích cảm xúc trong đánh giá khách sạn – mục tiêu của nó là phát hiện xem một bình luận có phải là tích cực hay tiêu cực, chứ không phải tạo ra các đánh giá giả. Các mô hình phân biệt vẫn là lựa chọn hàng đầu cho nhận dạng hình ảnh, phân loại tài liệu, phát hiện gian lận và nhiều nhiệm vụ kinh doanh hàng ngày khác.
Generative AI (Trí tuệ nhân tạo sinh tạo) có các ứng dụng kinh doanh vượt ra ngoài những gì được bao phủ bởi các mô hình discriminative models. Hãy xem những mô hình chung nào có thể được sử dụng để giải quyết một loạt các vấn đề khác nhau và đạt được kết quả ấn tượng.
Generative AI models and algorithms
Các mô hình và thuật toán trí tuệ nhân tạo sinh tạo
Các thuật toán và mô hình liên quan khác nhau đã được phát triển và huấn luyện (trained) để tạo ra nội dung mới, thực tế từ dữ liệu hiện có. Một số mô hình, mỗi cái với các cơ chế và khả năng riêng, đang đi đầu trong các lĩnh vực như tạo hình ảnh (image generation), dịch văn bản (text translation) và tổng hợp dữ liệu (data synthesis). Một số, như GANs, đã hơi lỗi thời nhưng vẫn được sử dụng.
Generative adversarial networks
Mạng đối kháng sinh tạo
Mạng đối kháng sinh tạo, hay GAN, là một khuôn khổ học máy đặt hai mạng nơ-ron – bộ tạo “generator” và bộ phân biệt “discriminator” – đối lập với nhau, do đó có “đối kháng” trong tên gọi. Cuộc tranh chấp giữa chúng là một trò chơi tổng bằng không, trong đó lợi ích của một bên là tổn thất của bên kia.
Mạng đối kháng sinh tạo (GANs) được phát minh bởi Jan Goodfellow và các đồng nghiệp của ông tại Đại học Montreal vào năm 2014. Họ mô tả kiến trúc GAN trong một bài báo có tựa đề “Mạng đối kháng sinh tạo”. Kể từ đó, đã có rất nhiều nghiên cứu và ứng dụng thực tế. GANs là thuật toán trí tuệ nhân tạo sinh tạo phổ biến nhất cho đến khi các mô hình dựa trên lan tỏa và transformer (bạn sẽ đọc về chúng bên dưới) gặt hái thành công gần đây.
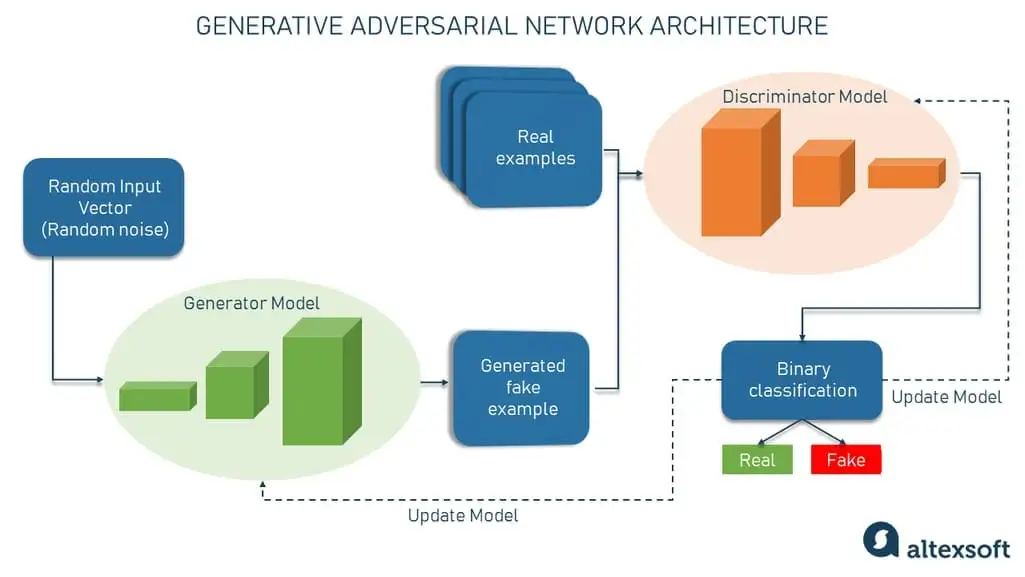
Trong kiến trúc của chúng, GANs có hai mô hình học sâu:
Bộ tạo “generator” – một mạng nơ-ron có nhiệm vụ tạo ra đầu vào giả hoặc mẫu giả từ một vector ngẫu nhiên (một danh sách các biến toán học có giá trị không xác định); và
Bộ phân biệt “discriminator” – một mạng nơ-ron có nhiệm vụ lấy một mẫu nhất định và quyết định xem nó có phải là một mẫu giả từ bộ tạo hay là một quan sát thực.
Bộ phân biệt cơ bản là một bộ phân loại nhị phân trả về các xác suất – một số giữa 0 và 1. Kết quả càng gần 0, càng có khả năng đầu ra sẽ là giả. Ngược lại, các số gần 1 cho thấy khả năng dự đoán là thực cao hơn.
Cả bộ tạo và bộ phân biệt thường được thực hiện dưới dạng mạng nơ-ron tích chập (CNN), đặc biệt khi làm việc với hình ảnh.
Vì vậy, bản chất đối kháng của GANs nằm trong một kịch bản lý thuyết trò chơi trong đó mạng tạo ra phải cạnh tranh với đối thủ. Mạng tạo ra trực tiếp tạo ra các mẫu giả. Đối thủ của nó, mạng phân biệt, cố gắng phân biệt giữa các mẫu được rút ra từ dữ liệu huấn luyện và những mẫu được rút ra từ mạng tạo ra. Trong kịch bản này, luôn có một người thắng và một người thua. Bất kỳ mạng nào thất bại sẽ được cập nhật trong khi đối thủ của nó vẫn không thay đổi.
GANs sẽ được coi là thành công khi một bộ tạo generator tạo ra một mẫu giả rất thuyết phục, đến mức có thể lừa được một bộ phân biệt discriminator và cả con người. Nhưng trò chơi không dừng lại ở đó; đã đến lúc bộ phân biệt discriminator phải được cập nhật và trở nên tốt hơn. Lặp lại.
Transformer-based models
Các mô hình dựa trên Transformer
Mô hình dựa trên Transformer được mô tả lần đầu tiên trong một bài báo của Google vào năm 2017, là một khuôn khổ học máy rất hiệu quả cho các tác vụ xử lý ngôn ngữ tự nhiên (NLP). Nó học cách tìm các mẫu trong dữ liệu tuần tự như văn bản viết hoặc ngôn ngữ nói. Dựa trên ngữ cảnh, mô hình có thể dự đoán phần tử tiếp theo của chuỗi, ví dụ như từ tiếp theo trong một câu. Nó rất phù hợp cho việc dịch và tạo văn bản.
Một số ví dụ nổi tiếng về các mô hình dựa trên Transformer là GPT-4 của OpenAI và Claude của Anthropic
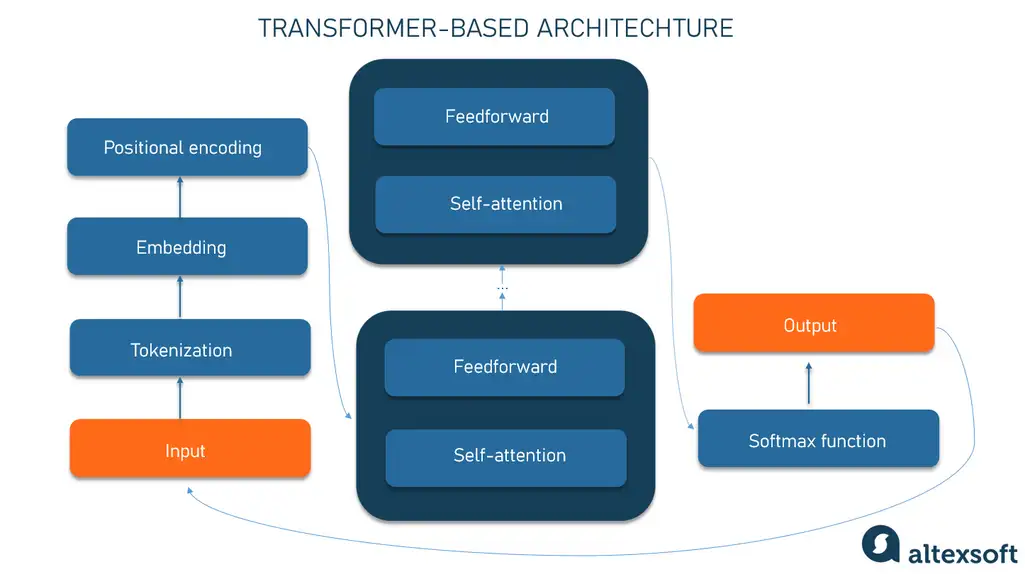
Hãy cùng xem xét từng bước về cách một mô hình dựa trên Transformer hoạt động.
Tokenization. Trong các mô hình transformer, quá trình tokenization là việc chia dữ liệu đầu vào thành các phần nhỏ hơn gọi là token. Đối với văn bản, các token có thể là từ, các phần từ hoặc ký tự. Ví dụ, câu “The quick brown fox jumps over the lazy dog” có thể được tokenized thành các token như “The”, “quick”, “brown”, “fox”, “jumps”, “over”, “the”, “lazy”, “dog”.
Embedding. Các token đầu vào được chuyển đổi thành các vector số học được gọi là embedding. Mỗi token được biểu diễn bởi một vector duy nhất (một tập hợp các số thực). Một vector biểu diễn các đặc trưng ngữ nghĩa của một từ, với các từ tương tự có các vector gần giá trị. Ví dụ, từ crown có thể được biểu diễn bằng vector [3,103,35], trong khi apple có thể là [6,7,17], và pear có thể trông giống như [6.5,6,18]. Tất nhiên, những vector này chỉ mang tính minh họa; những vector thực tế có nhiều chiều hơn.
Positional encoding. Mã hóa vị trí. Để hiểu văn bản, thứ tự của các từ trong một câu quan trọng không kém so với chính các từ đó. Vì vậy, ở giai đoạn này, thông tin về vị trí của mỗi token trong một chuỗi được thêm vào dưới dạng một vector khác, được tóm gọn với một embedding đầu vào. Kết quả là một vector phản ánh ý nghĩa ban đầu của từ và vị trí của nó trong câu.
Nó sau đó được cấp vào mạng nơ-ron transformer, bao gồm hai khối.
Self-attention mechanism Cơ chế chú ý tự động tính toán các mối quan hệ ngữ cảnh giữa các token bằng cách xác định tầm quan trọng của mỗi phần tử trong một chuỗi và xác định độ mạnh của các mối liên kết giữa chúng. Về mặt toán học, các mối quan hệ giữa các từ trong một cụm từ trông giống như khoảng cách và góc giữa các vector trong không gian vector đa chiều. Cơ chế này có thể phát hiện những cách tinh tế mà ngay cả các phần tử dữ liệu xa cách trong một chuỗi cũng ảnh hưởng và phụ thuộc vào nhau.
Ví dụ, trong câu “I poured water from the pitcher into the cup until it was full” và “I poured water from the pitcher into the cup until it was empty” (“Tôi đổ nước từ bình vào cốc cho đến khi nó đầy” và “Tôi đổ nước từ bình vào cốc cho đến khi nó trống”,), một cơ chế chú ý tự động (self-attention mechanism) có thể phân biệt ý nghĩa của từ “it” (nó) : Trong trường hợp trước, đại từ này chỉ cốc, trong trường hợp sau chỉ bình.
The feedforward network (refines token representations) Mạng feedforward tinh chỉnh các biểu diễn token bằng cách sử dụng kiến thức về từ mà nó đã học từ dữ liệu huấn luyện (nhưng thành thật mà nói, thậm chí đối với các nhà khoa học, việc giải thích chính xác những gì nó làm cũng là một thách thức).
The self-attention and feedforward stages được lặp lại nhiều lần qua các lớp xếp chồng, cho phép mô hình nắm bắt các mẫu ngày càng phức tạp trước khi tạo ra đầu ra cuối cùng.
The softmax function is used at the end to calculate the likelihood of different outputs and choose the most probable option.
Sau đó, đầu ra (generated output) được tạo ra được nối vào đầu vào, và toàn bộ quá trình lặp lại.
Diffusion models
The diffusion model is a generative model that creates new data, such as images or sounds, by mimicking the data on which it was trained.
mô hình sinh tạo tạo ra dữ liệu mới, như hình ảnh hoặc âm thanh, bằng cách bắt chước dữ liệu mà nó được huấn luyện.

Hãy nghĩ “diffusion model” như một nghệ sĩ-nhà phục chế đã nghiên cứu các bức tranh của các họa sĩ cổ điển và giờ đây có thể vẽ lại những bức vải của họ theo cùng một phong cách. Mô hình lan tỏa làm điều tương tự theo ba giai đoạn chính.
Direct diffusion từ từ đưa nhiễu vào hình ảnh gốc cho đến khi kết quả chỉ là một tập hợp hỗn loạn các điểm ảnh.
Nếu chúng ta quay lại ví dụ về nghệ sĩ-nhà phục chế, direct diffusion được xử lý bởi thời gian, phủ lên bức tranh một mạng lưới các vết nứt, bụi và mỡ; đôi khi, bức tranh được làm lại, thêm vào một số chi tiết và loại bỏ những chi tiết khác.
The learning stage: Giai đoạn học tập giống như việc nghiên cứu một bức tranh để nắm bắt ý định ban đầu của họa sĩ cổ điển. Mô hình cẩn thận phân tích cách thức mà nhiễu được thêm vào làm thay đổi dữ liệu. Nó cẩn thận theo dõi đường đi từ hình ảnh gốc đến phiên bản hỗn loạn của nó, học cách phân biệt giữa dữ liệu gốc và dữ liệu bị sai lệch tại mỗi bước. Sự hiểu biết này cho phép mô hình có thể hiệu quả đảo ngược quá trình sau này.
Sau khi học tập, mô hình này có thể tái tạo lại dữ liệu bị sai lệch thông qua quá trình được gọi là reverse diffusion. Nó bắt đầu từ một mẫu nhiễu và loại bỏ dần các vết mờ – cùng một cách mà nghệ sĩ của chúng ta loại bỏ các tạp chất và sau đó lớp sơn. Kết quả là dữ liệu mới gần với dữ liệu gốc – chẳng hạn như một bức ảnh của một con chó, nhưng không phải chính xác là con chó như trong hình ảnh gốc.
Kỹ thuật này cho phép các mô hình diffusion models tạo ra các hình ảnh, âm thanh và các loại dữ liệu khác một cách thực tế.
Midjourney và DALL-E là hai công cụ tạo hình ảnh nổi tiếng dựa trên các mô hình diffusion models.
Phần 2: https://kenkai.vn/giao-duc/giai-thich-cac-mo-hinh-tri-tue-nhan-tao-tao-sinh-%f0%9f%a4%96phan-2/
Tác giả: altexsoft.com,
Link bài gốc: Generative AI Models Explained | Bài được cập nhật lần cuối vào Ngày 05 tháng 09 năm 2024 | www.altexsoft.com
Dịch giả: Dieter R – KenkAI Nhiều thứ hay
(*) Bản quyền bản dịch thuộc về Dieter R. Tuy nhiên, nội dung bài viết không phải do tôi tạo ra. Mọi khiếu nại về bản quyền (nếu có) xin vui lòng gửi email đến địa chỉ purchasevn@getkenka.com. Xin chân thành cảm ơn.
(**) Follow KenkAI Nhiều thứ hay để đọc các bài dịch khác và cập nhật thông tin bổ ích hằng ngày.
Để lại một bình luận